
本篇希望可以帮大家梳理两件事:
- 有哪些:大家可以调用的模型都有谁?
- 怎么选:对比AI助理可用模型差异优势
- 如何用:手把手教大家添加自定义模型
可用模型列表
在哪找?
模型列表及价格页面:点击查看
可使用模型包括来自以下品牌的最新模型:
✅ OpenAI:gpt-4o、gpt-4、gpt-4-all全系列模型同步更新
✅ Midjourney:AI绘画
✅ Claude:全系列编程最强
✅ Gemini:谷歌推出 Gemini 1.0/1.5 系列
✅ Suno:文生歌曲
✅ Luma:文生视频、图生视频
以及国内模型Kimi、阿里千问、百度千帆、质谱AI、DEEPSEEK、百川智能、零一万物、讯飞星火、字节豆包、商汤、langchain、腾讯混元等等均支持。
日常使用推荐
1. 【首推】功能最全:GPT-4-all
强大的多模态能力,集合官方GPT-4、GPTs、联网、数据分析、读图、绘图功能、code interpreter代码解释器一体,和官方体验完全一致。
2. 【日常】性价比最优:gpt-4o
速度超快,具有 128K 上下文,2023 年 10 月的知识截止点,gpt-4o-后边一般会跟日期比如 gpt-4o-2024-08-06 ,代表在2024年8月6日推出的版本,建议尽量选择更新的版本。
3. 【便宜】低到极致:gpt-4o-mini
GPT-4o Mini主打的就是便宜好用,该模型具有 128K 上下文与极低价格:
Input Tokens: $0.38/M tokens 每百万tokens
Output Tokens: $1.5/M tokens 每百万tokens
token与单词的换算比例大约为 1000tokens=750单词 ,也就是说大约输入100万tokens(75万单词),你需要消耗0.38美金,按照网站充值汇率1美金=2人民币,约0.76人民币(7毛6);输出100万tokens(75万单词),你需要消耗1.5美金约3人民币,价格非常低廉。
4. 【编程】代码厉害:claude-3-5-sonnet-20240620
如果你有写代码的需求,建议使用Claude 3.5 sonnet,具有最先进的语言处理技术,支持200K上下文、可读取图片,擅长推理及代码。
5. 【识图】任意模型
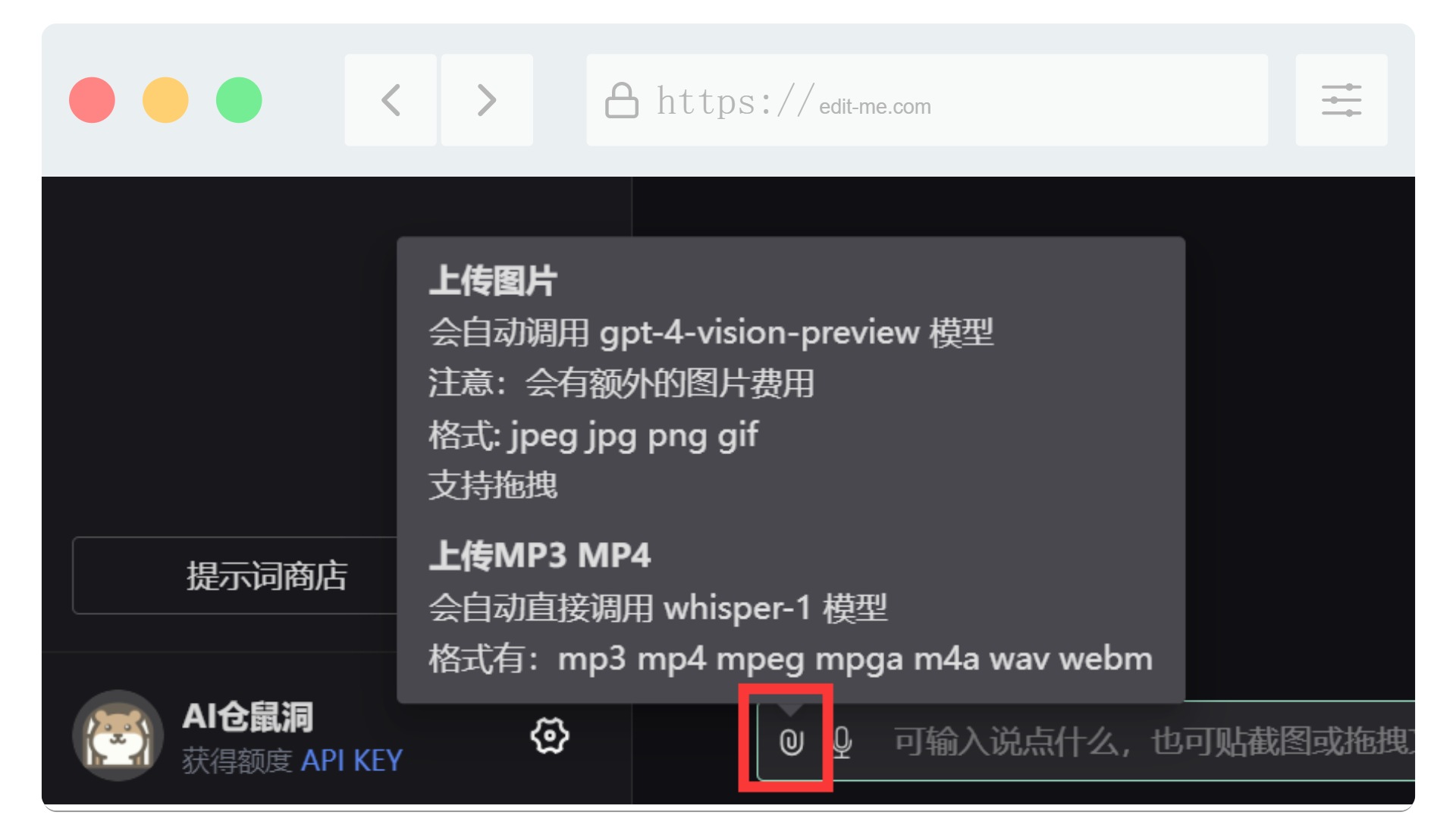
大多数模型支持(除了gpt-4-all),把鼠标放在对话框左侧的上传图标上,可以看到上传图片、上传音视频后的处理方式,如上图显示:
- 上传音视频会自动调用whisper-1模型转文字
- 上传图片会自动调用vision模型进行查看和描述
6. 【转录】任意模型
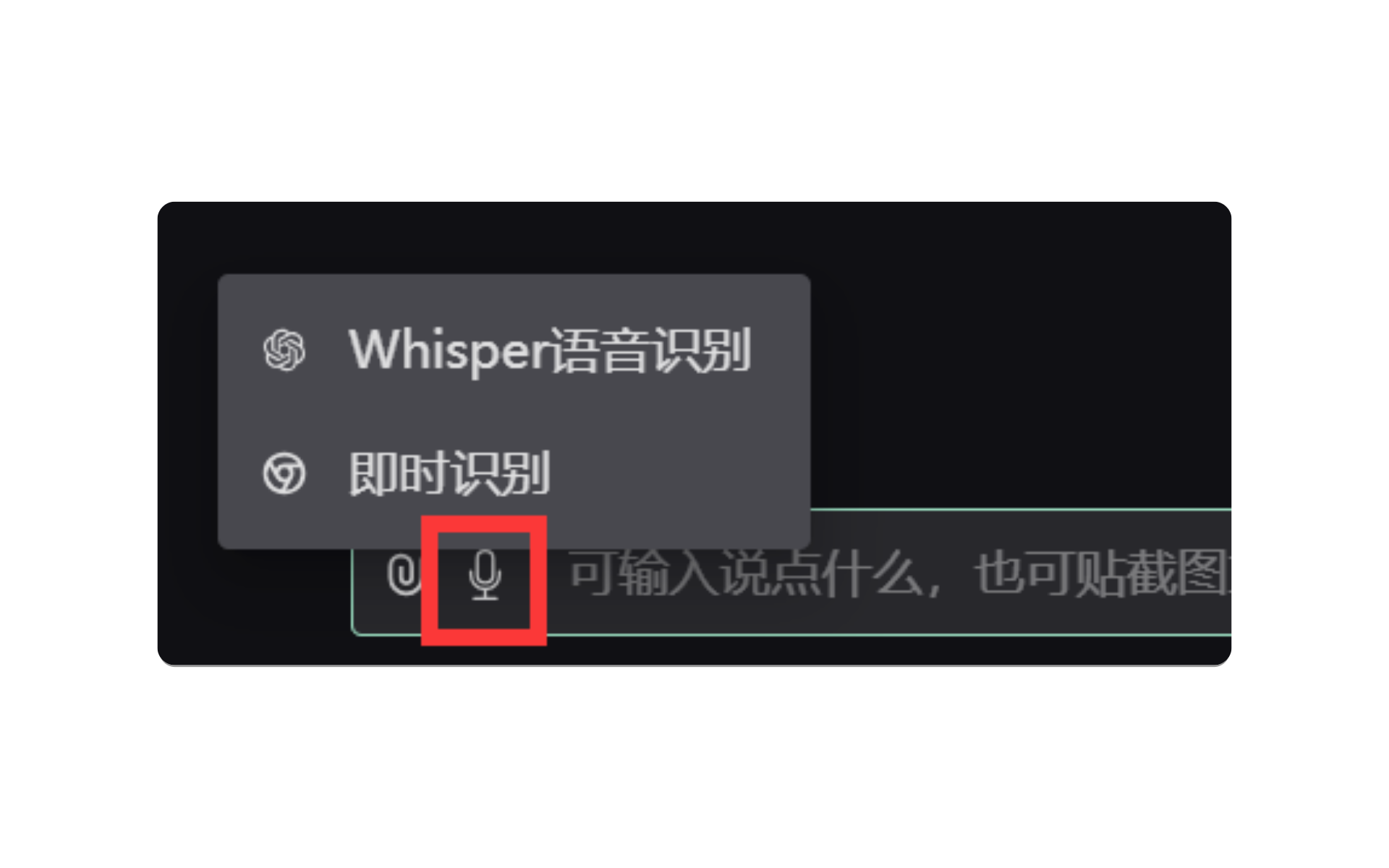
大多数模型支持(除了gpt-4-all),把鼠标放在输入框左侧小话筒,你可以使用Whisper现场录制或即时识别。
7. 【TTS】文本转语音
借助OPEN AI强大文本转语音模型,你有两种使用方式:
1. 把AI回复的内容转为语音
只需要点击对话右侧三个小点,选择TTS文本转语音即可。
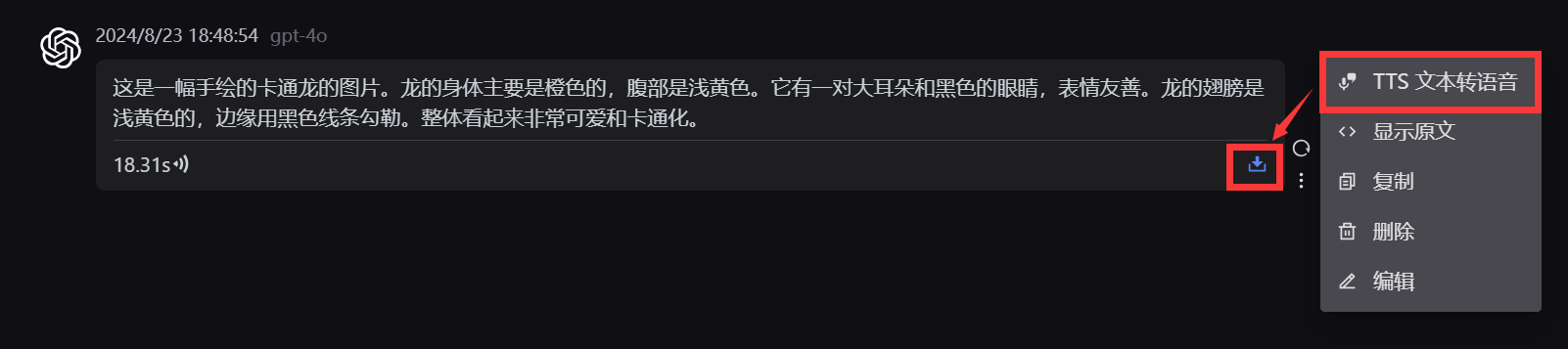
2. 把你输入的任何内容转换为语音
需要使用自定义的tts模型,然后输入任何内容,会自动生成音频,方便你在视频剪辑中使用。自定义模型的方法,请看本篇内容的最后的 添加自定义模型 部分,目前TTS模型建议选择以下两种:
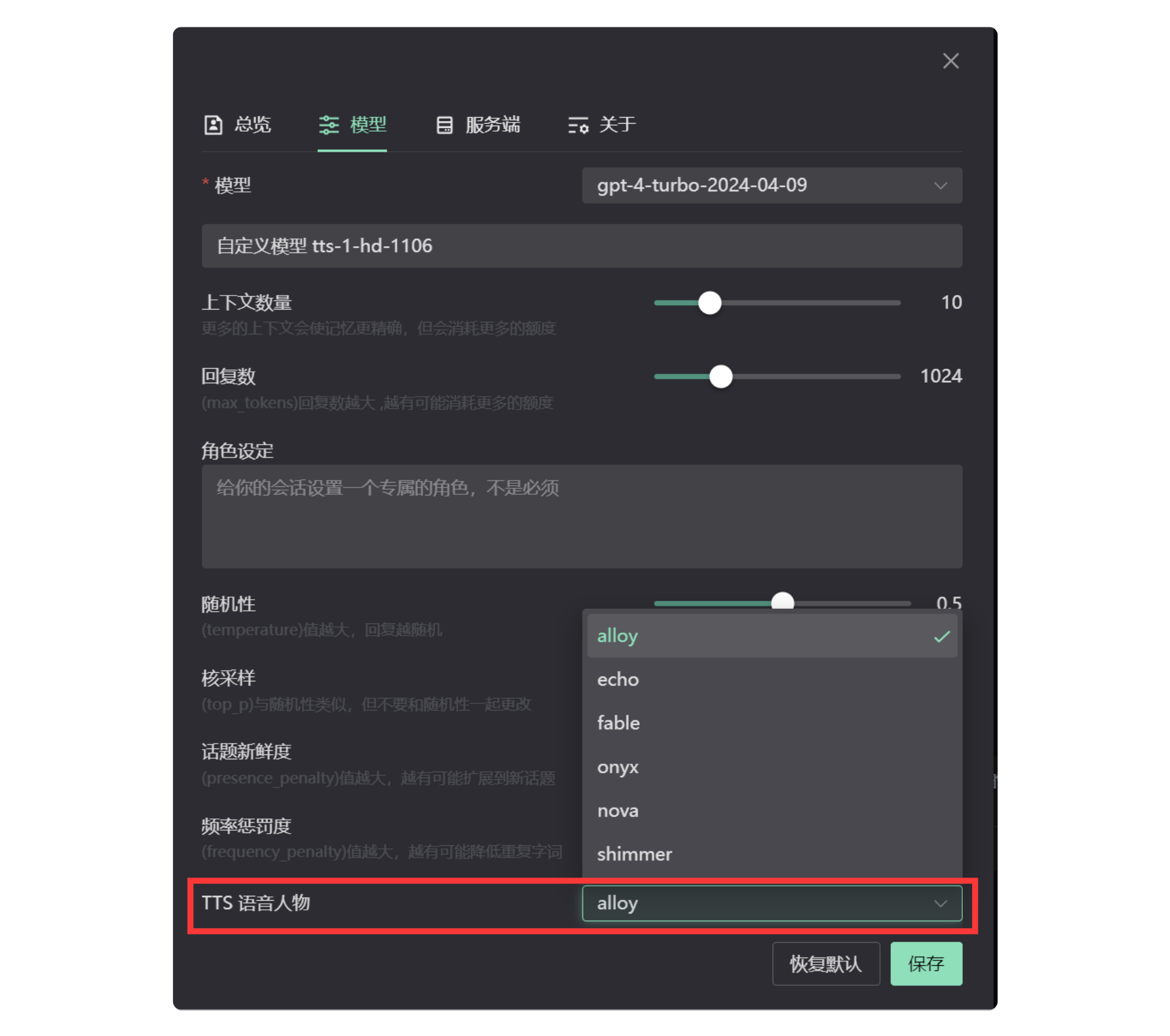
tts-1-1106tts-1-hd-1106设定你喜欢的音色
打开【设置】界面,选择【模型】,点击右下角的 More ,选择一位TTS语音人物即可。
8. 【数据】数据分析:GPT-4-all
上传Excel或csv数据集进行数据读取、清洗、分析、可视化等工作。
如何添加自定义模型?
理论上在模型列表页面中你看到的所有模型都可以使用,配置方法很简单,我们这里以添加 tts语音模型 为例。
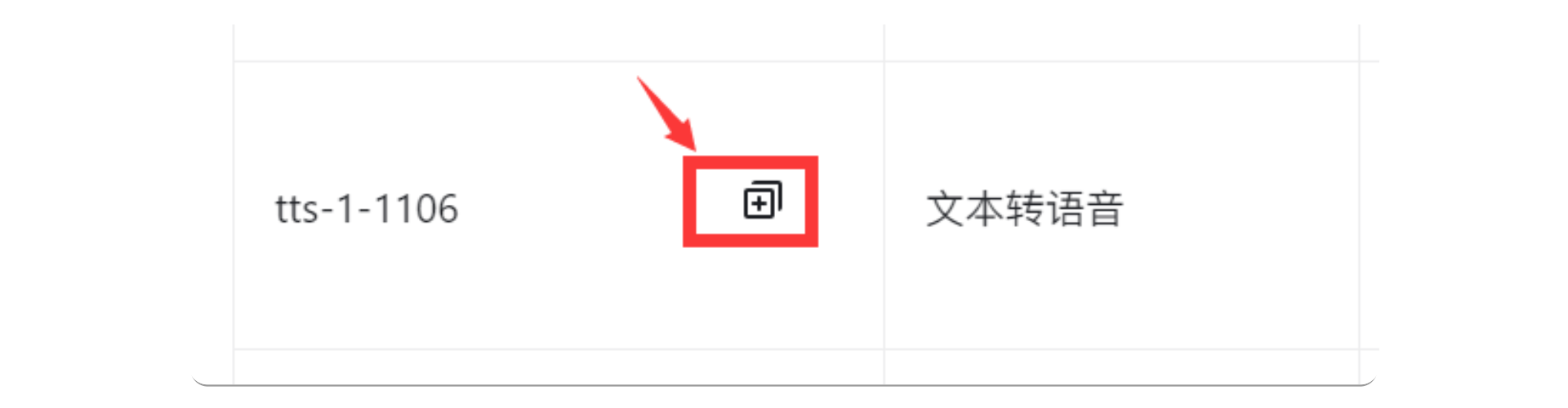
1. 复制模型名称
在模型列表页面,找到 tts-1-1106 ,并复制它的名称。
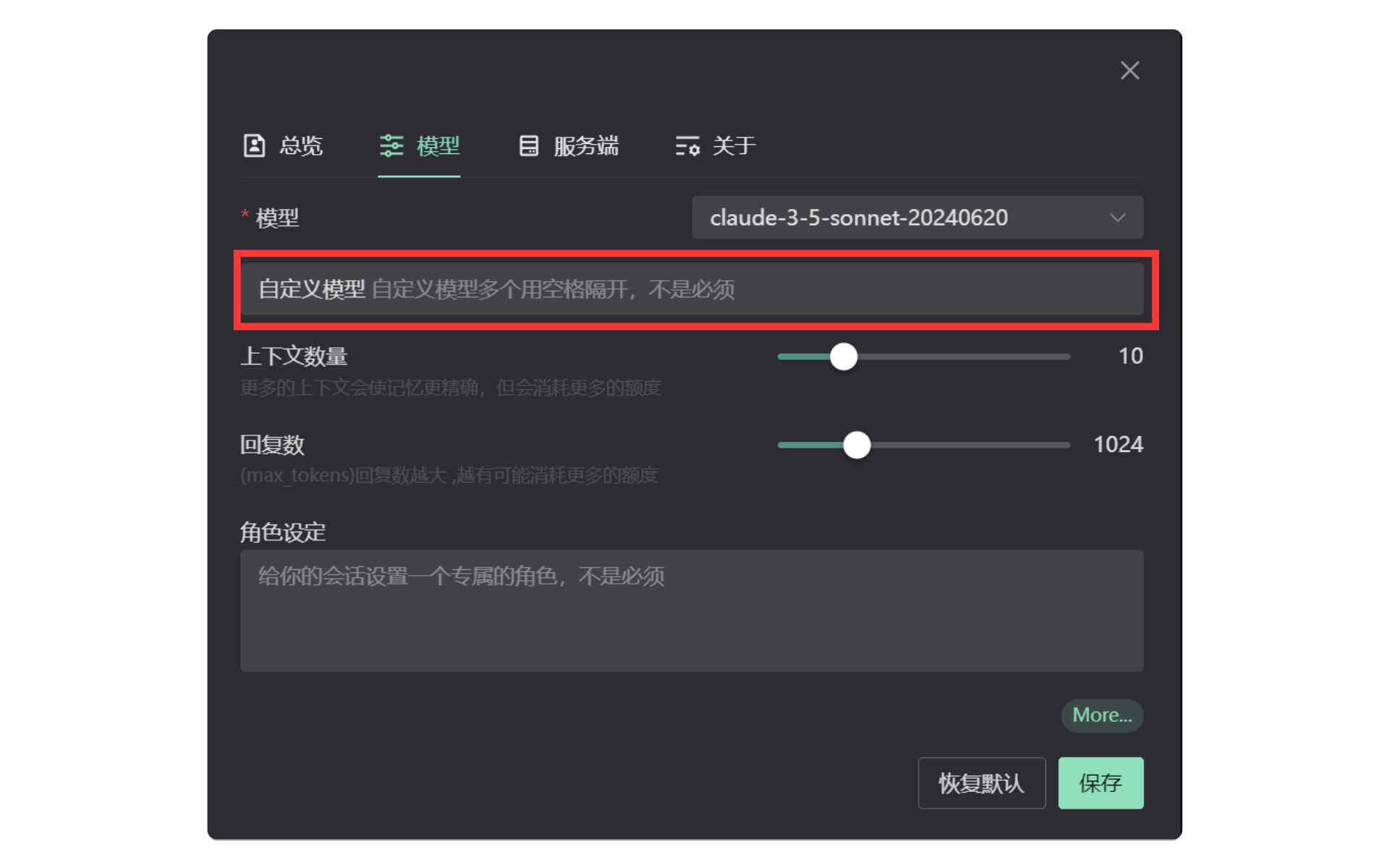
2. 打开设置-模型
回到AI助理页面,点击左下角齿轮打开【设置-模型】。
3. 输入自定义模型名称
在 自定义模型 的位置粘贴 tts-1-1106 ,点击【保存】即可。
tts-1-1106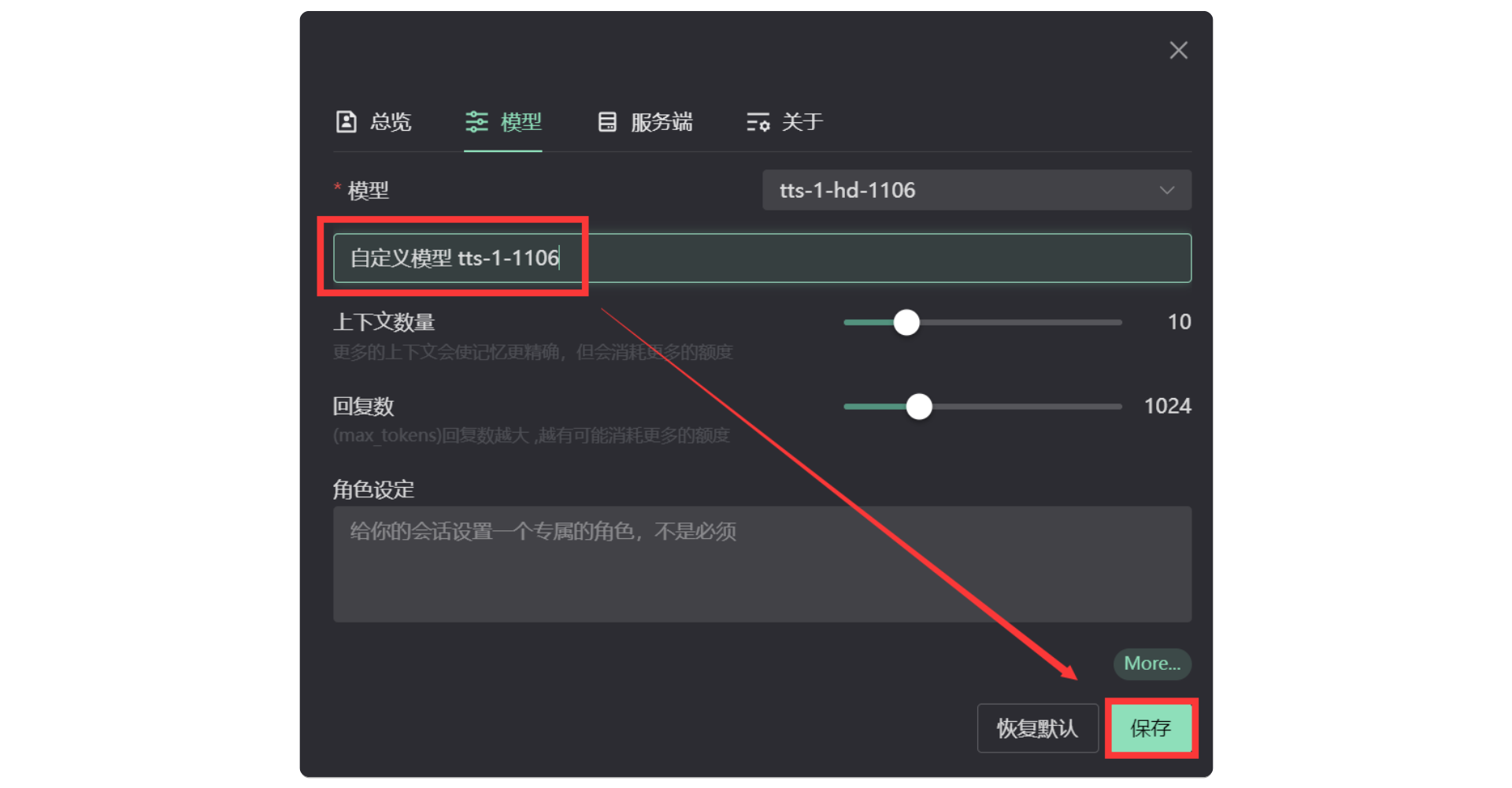
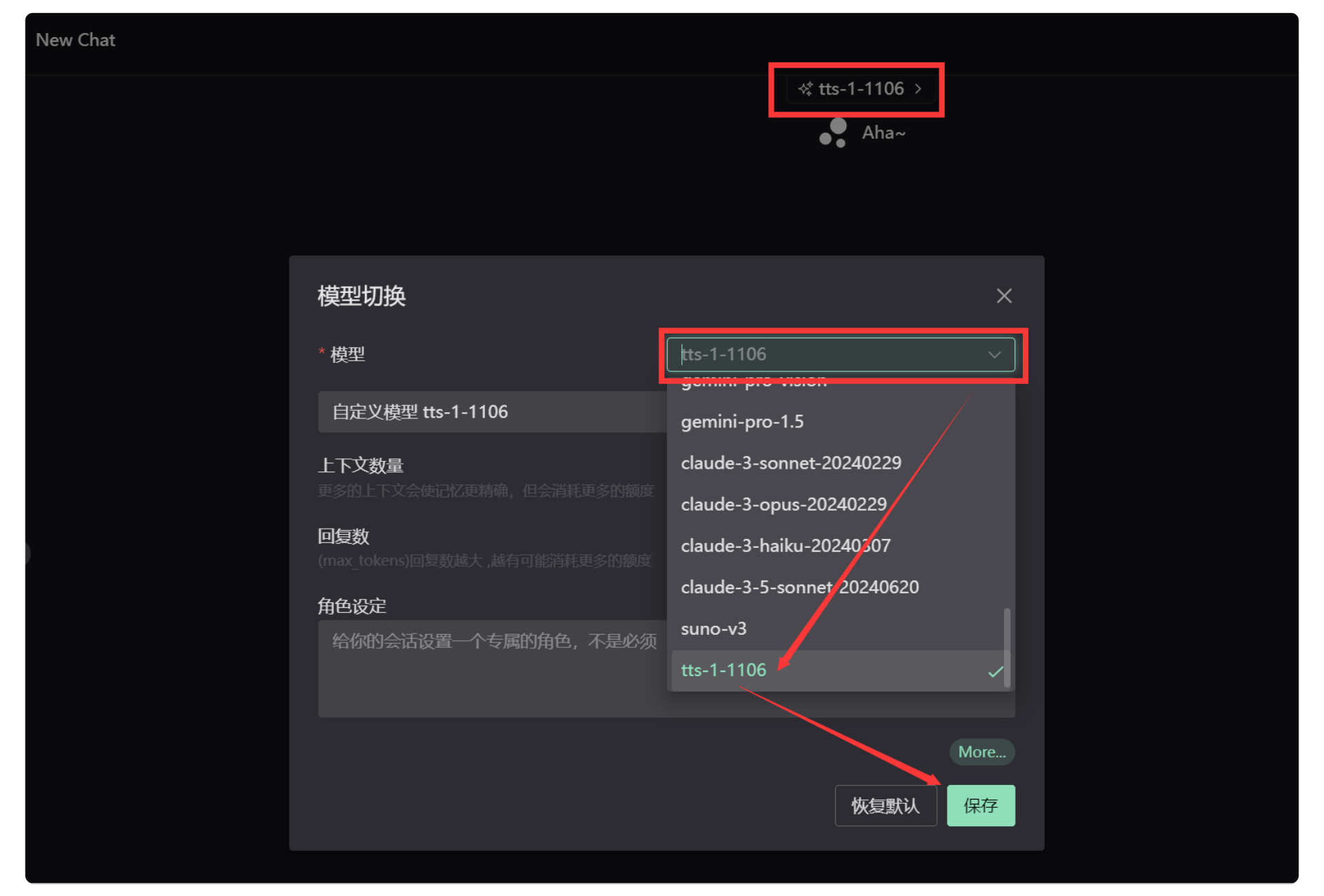
4. 使用新模型
【新建聊天】后,点击上方模型名称,选择模型 tts-1-1106 开始使用。
其他所有模型自定义的方法都一模一样。
{kind=link}