
本系列是AI仓鼠洞针对DeepSeek的从入门到日常应用完成教程,持续更新。本篇【学前班】争取带大家先一次全面了解DeepSeek是什么和怎么开始使用。
什么是DeepSeek?
一款世界领先的大语言模型,或者说AI助手。结合了数据搜索、分析、理解和推理,可以帮助用户高效处理和分析数据、生成内容、优化工作流程等。
推荐阅读:1分钟简单认识DeepSeek
为什么就它爆火?
如果一句话说就是:便宜+强大+开源+能联网,东方神秘力量Appstore排行第一,导致算力股大跌。
拆分来看就是3点:
-
便宜:
- 网页端和APP都免费,而能力相当的 ChatGPT o1 一个月 200 美元会员。
- API 调用成本相比 OpenAI o1 降低了 90-95%(恐怖)
-
强大:Chatbot Arena榜单上,DeepSeek-R1 性能综合排名第三,与 ChatGPT o1 并列,在高难度提示词、代码和数学等技术性极强的领域以及风格控制方面,DeepSeek-R1 位列第一。
-
开源:与Close AI形成对比,任何人都可以自由地使用、修改、分发和商业化该模型,彻底打破了以往大型语言模型被少数公司垄断的局面。
我的使用体会
- 功底过硬,能力与OpenAI最强的o1跑分持平,但DeepSeek开源
- 实测惊艳,这几天大家在网上看到的各种文案输出已经有感觉
- 很多文风已经以假乱真,你根本分不出是不是AI创作,不信你看这篇
- 以往通用模型的结构化提示词,用在R1上效果却不一定好
- 那提示框架还有用吗?有用,因为提示词本身的目的是“清晰表达”,无论是么时候都有用,只是这个措辞过程会越来越简单
- 如果你有既定的解题思路或输出格式需要遵循,还是可以应用提示框架
- 之前的通用模型是指令型,像是需要你事无巨细指导的实习生;R1是推理大模型,像是猎头刚刚挖来的职业经理人,告诉TA你的目标,他会自己思考如何实现
- 如我之前一直所说,模型越厉害,提示技巧越简单
关于我学习和理解AI的更多思路,去年写得这篇我很喜欢,现在大家看看依然有参考价值:https://weibo.com/1794009892/OwdjKncJv?pagetype=detail
如何使用?
1. 官方途径
- 电脑:www.deepseek.com
- 手机:打开应用市场,搜索“DeepSeek”下载即可
- 记得必须勾选【深度思考】激活R1模型
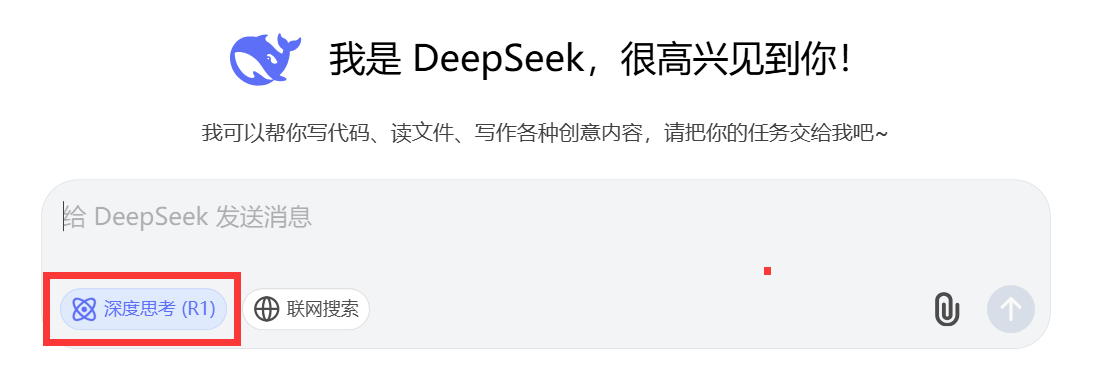
勾选【深度思考】、【联网搜索】和什么都不勾选的三种模式区别对比如下:
| 对比维度 | 深度思考(R1) | 联网搜索 | 默认模式(V3) |
|---|---|---|---|
| 核心能力 | 复杂逻辑推理、多角度结构化分析 | 实时获取互联网最新信息并整合 | 快速回答常识性问题 |
| 数据来源 | 预训练知识库(截至2024年7月) | 实时网络抓取(截至当前时间) | 预训练知识库(可能过时) |
| 处理方式 | 思维链展开、贝叶斯推理框架 | 搜索+信息筛选+多源交叉验证 | 直接调用模型记忆 |
| 响应速度 | 较慢(需模拟人类思考过程) | 中等(需等待网络检索) | 极快(平均1秒内) |
| 典型优点 | 1. 解决数学/代码难题 2. 生成结构化报告 |
1. 时效性强 2. 附带来源引用 |
1. 即问即答 2. 资源消耗低 |
| 主要缺点 | 可能过度复杂化简单问题 | 受网站反爬机制限制 | 无法处理时效性问题 |
| 适用场景举例 | • 学术论文逻辑推演 • 职业规划分析 |
• 查询奥运会新增项目 • 追踪股市动态 |
• 水的化学式 • 历史事件简述 |
2. 推荐满血版平替
由于官方总是提示“服务器繁忙,请稍后再试”,近期使用可以考虑以下6个替代方案,间接使用 满血版 DeepSeek R1 模型。
1. DeepSeek 点开即用
目前搜索AI很多接入了R1满血模型,优势是点开即用,最方便的推荐。
1. 【首推】硅基流动
获取API后,你有两个选择:
- 直接在硅基流动官网使用DeepSeek
- 借助客户端使用DeepSeek
如果在官网使用,直接打开 https://cloud.siliconflow.cn/models
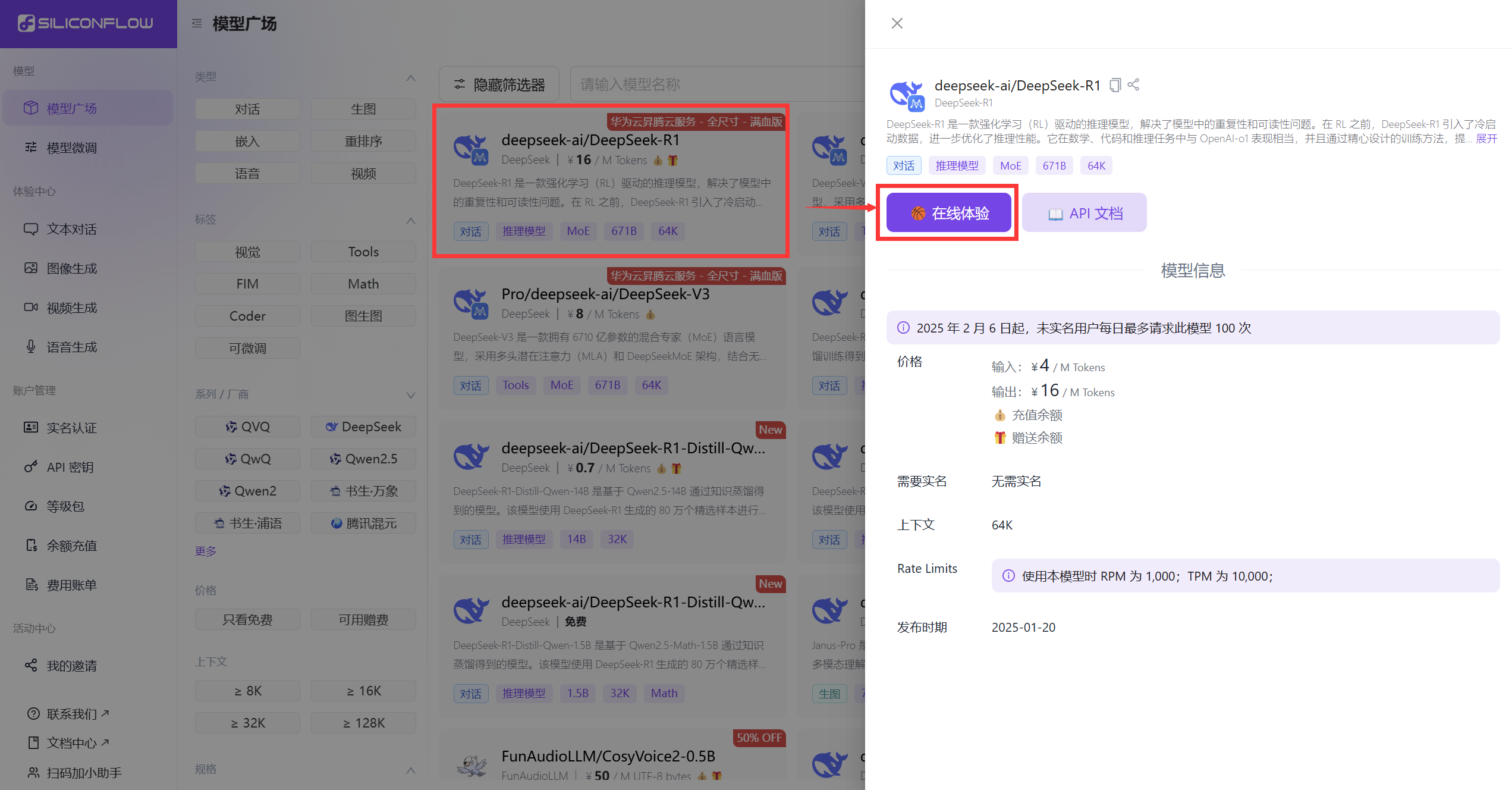
如上图,找到 R1 模型,点击进入-在线体验,即可开始正常对话。
如果你希望对话更稳定,界面更友好,可以往下看,使用第三方客户端接入R1。
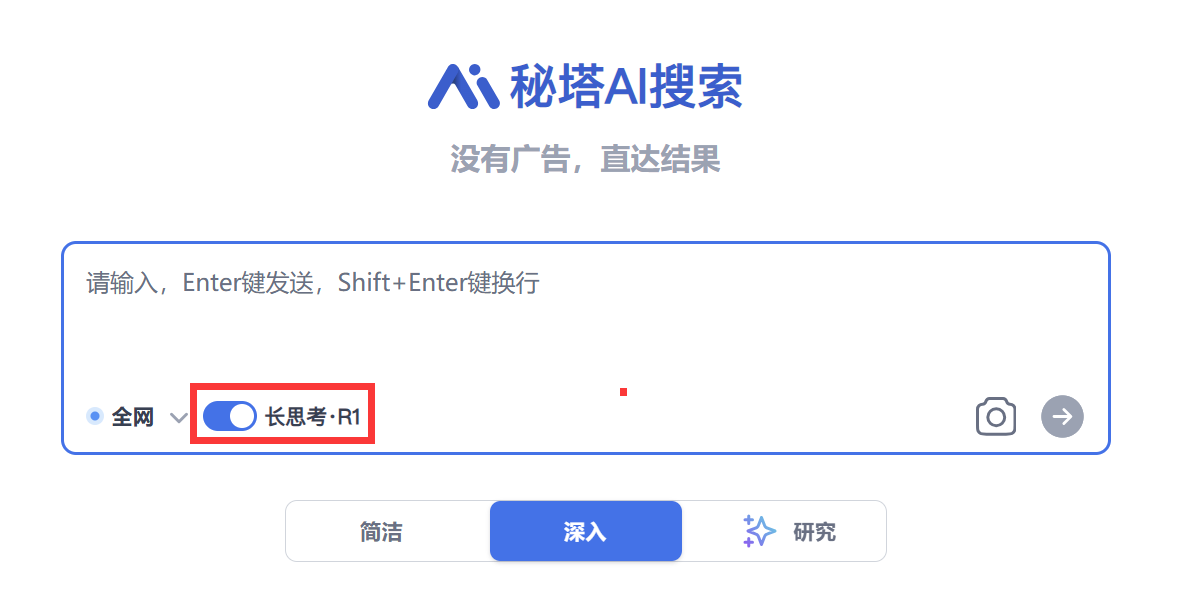
2. 秘塔搜索:https://metaso.cn/
如果你需要 联网搜索 + DeepSeek R1推理,那么秘塔是首选,除了秘塔之外,腾讯元宝、纳米搜索、天工AI也是类似的 搜索+DeepSeek 模式。
网页地址:https://yuanbao.tencent.com/
手机APP:应用商店搜索「秘塔AI搜索」
3. 腾讯元宝:https://yuanbao.tencent.com/
支持手机端和网页端,先切换为 DeepSeek R1 模型,然后搜索问题即可。
网页地址:https://yuanbao.tencent.com/
手机APP:应用商店搜索「腾讯元宝」

4. 纳米搜索:https://www.n.cn/
适合移动端用户快速调用 AI 能力,尤其适合碎片化场景(如通勤、会议记录)。
使用步骤
- 应用商店搜索「纳米 AI 搜索」APP 下载安装;
- 输入问题,开启「深度回答」按钮调用满血版模型。
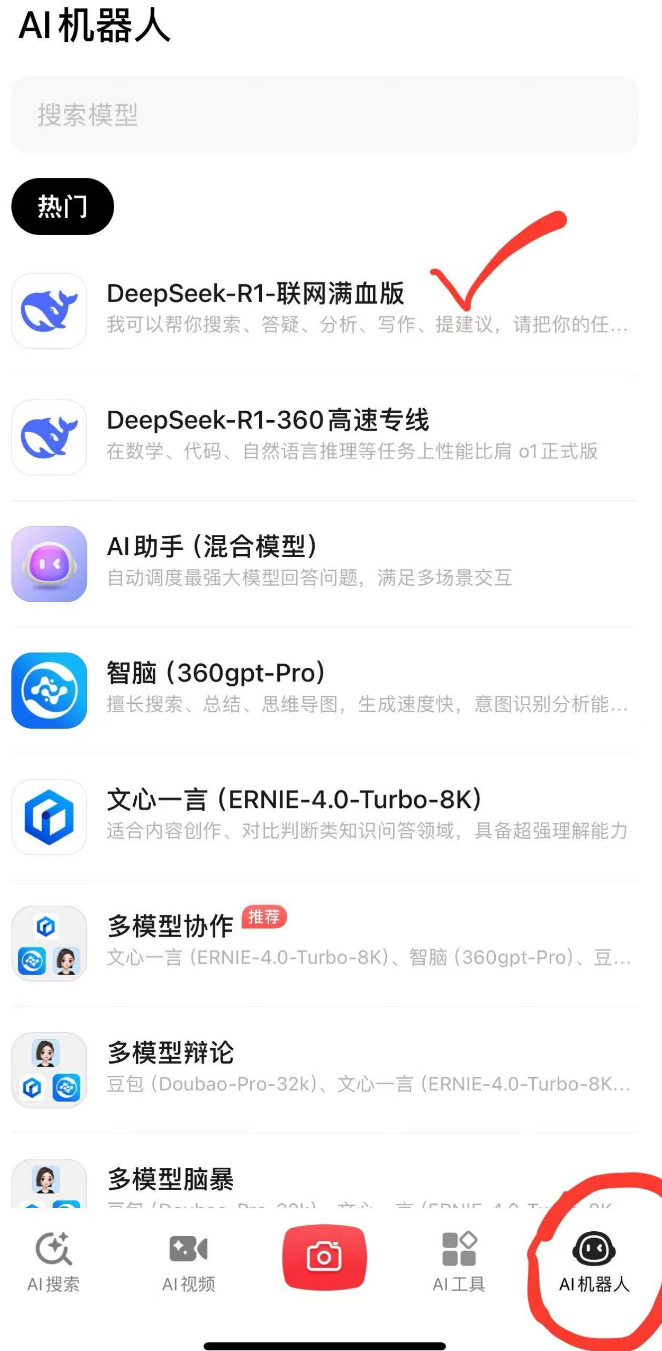
- 如果你的目标不是「搜索」,而是「对话」,那么点击下方【机器人】,选择
DeepSeek-R1-联网满血版开启对话。
5. 天工AI:https://www.tiangong.cn/
网页地址:https://www.tiangong.cn/
手机APP:应用商店搜索「天工」

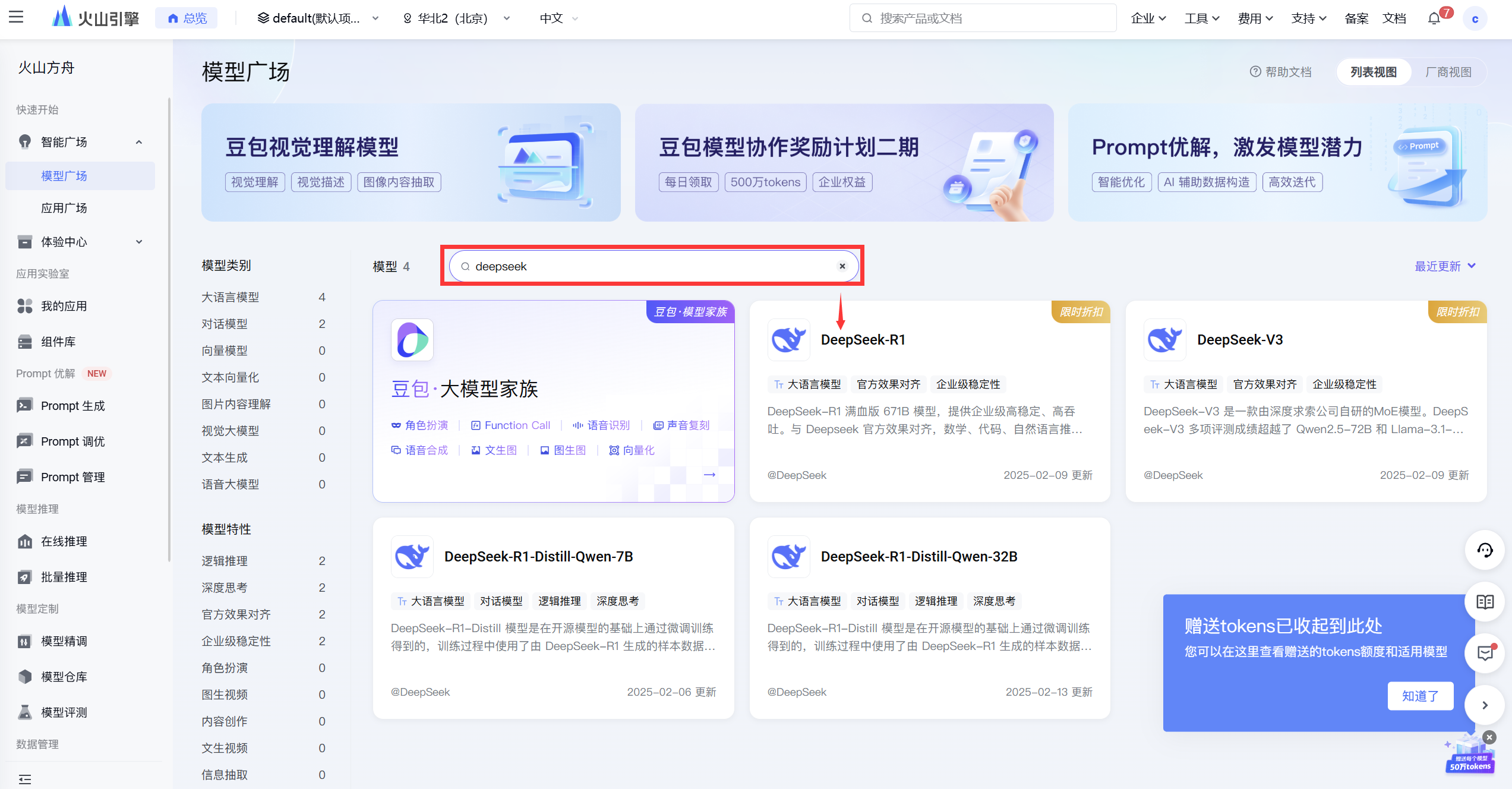
6. 火山引擎
进入火山引擎后,会免费赠送50万token额度,在模型广场搜索找到 DeepSeek-R 点击【立即体验】,即可开始已使用。
2. DeepSeek API + 第三方客户端
获取DeepSeek的稳定API+使用API,API你可以理解为大模型能力的接口,接给谁,谁就拥有和大模型一样的超能力,那么就简单了。
那很明显,这种方式你需要准备两个东西: API 和 客户端。
第1步:获取API推荐
【首推】硅基流动API
硅基流动目前官方活动:使用邀请链接注册就送 2000 万 Token,对话输入和输入数量大致相当于1000万汉字,足够大家免费使用一段时间啦。
第2步:下载客户端
- 【首推】Chatbox:https://chatboxai.app/zh
- 【备选】Cherry Studio:https://cherry-ai.com/download
具体操作教程
-
获取API:点击注册硅基流动账号获取
-
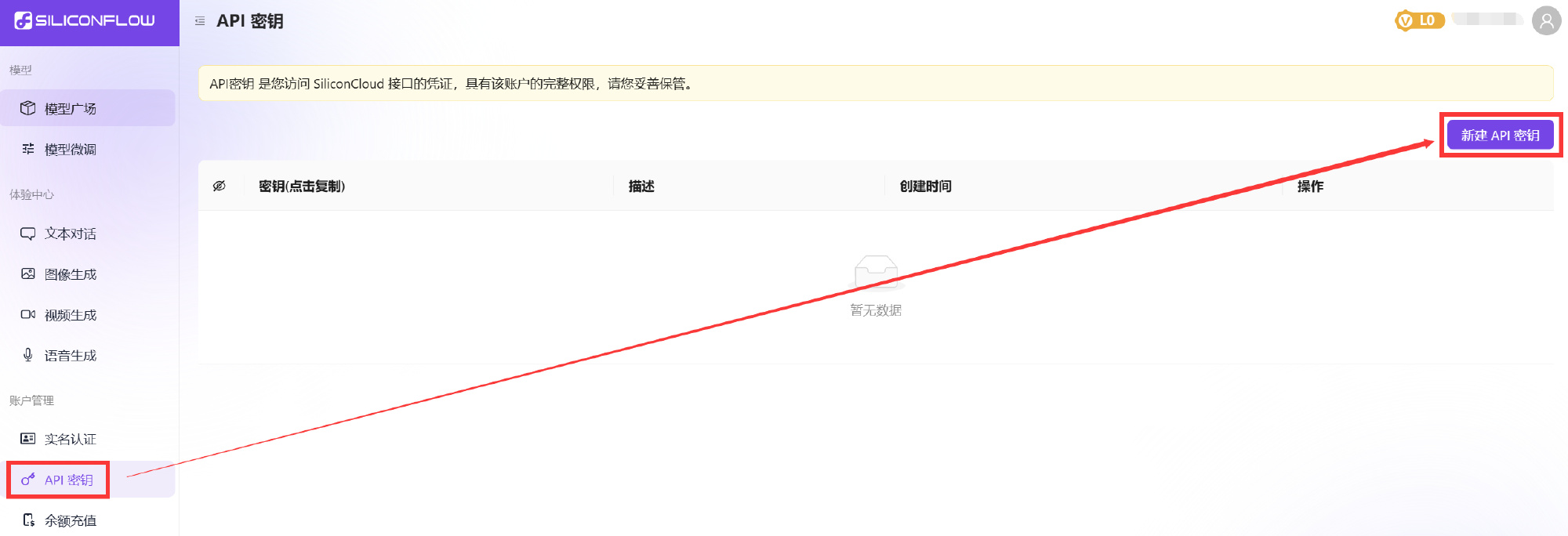
进入硅基流动平台后,点击左侧边栏【API密钥-新建API密钥】
-
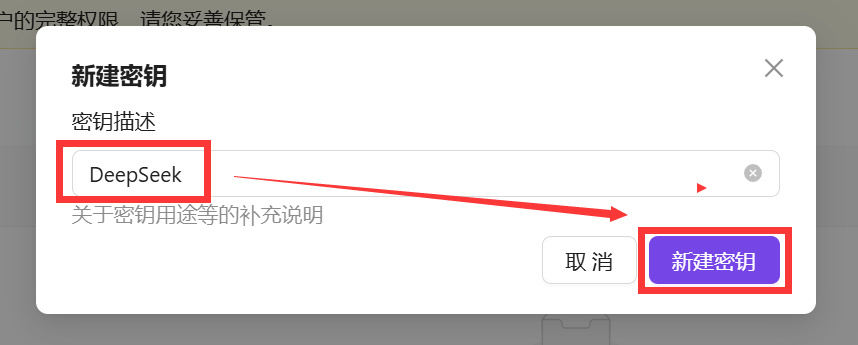
命名为DeepSeek,点【新建密钥】
-
新页面中,鼠标悬停在密钥上,单击复制,搞定!

-
使用 API
打开chatbox(在线):https://web.chatboxai.app/
或者下载Chatbox客户端(稳定):https://chatboxai.app/zh -
点击【设置-显示】,语言为中文

-
点击【模型-Siliconflow API】即硅基流动
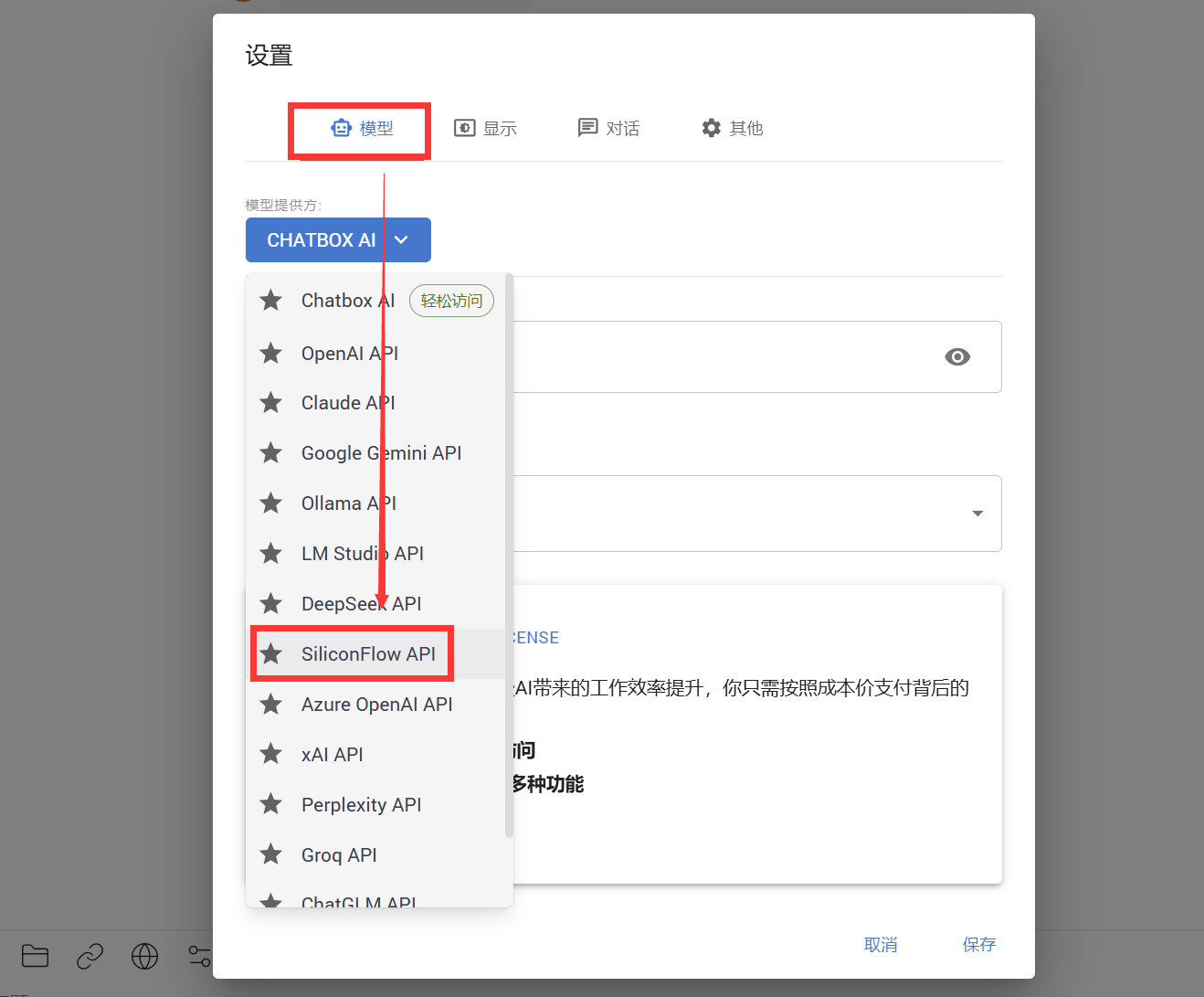
-
粘贴刚刚获取到的API,并且下方模型确保选择【DeepSeekR1】
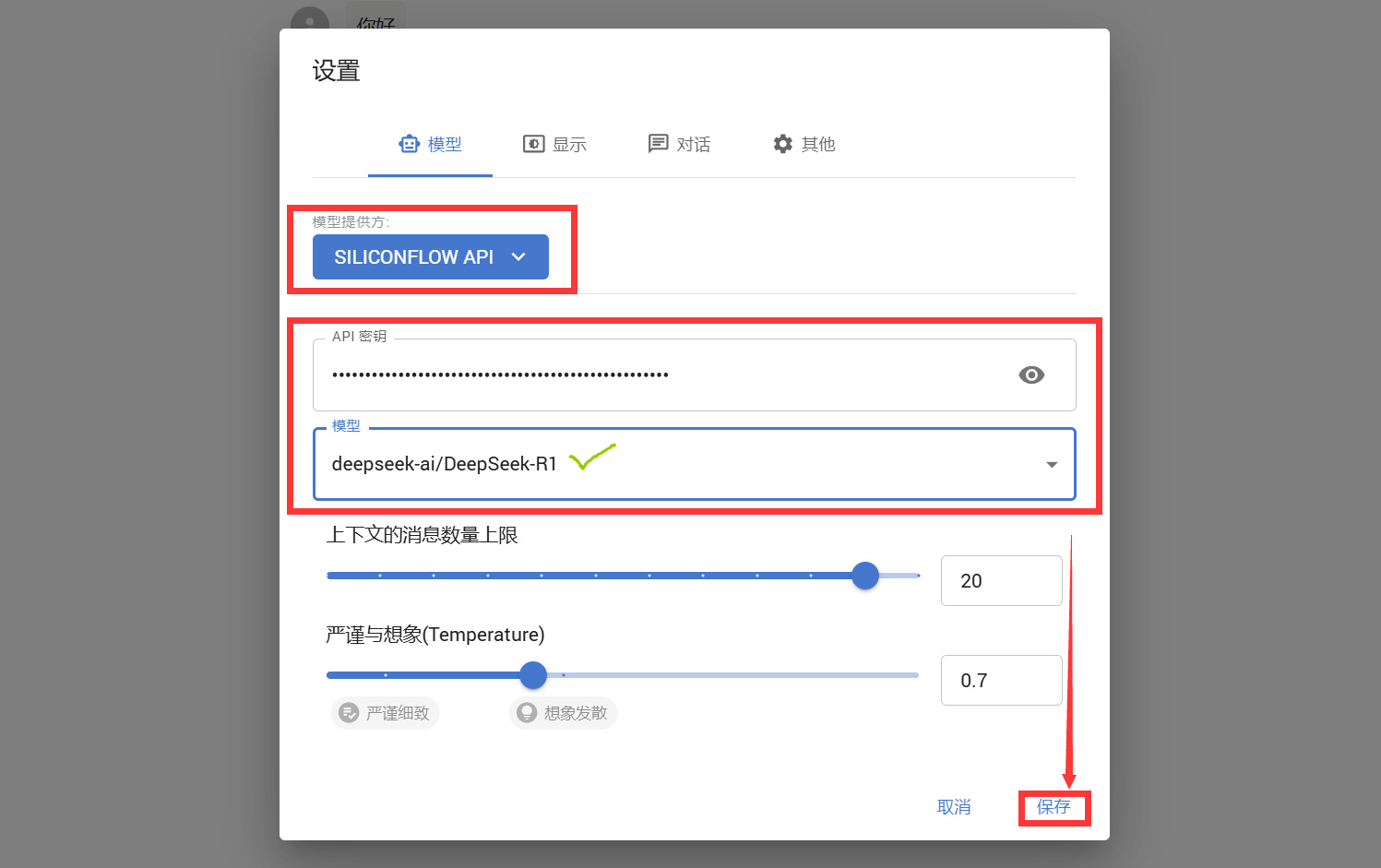
-
搞定!你可以回到主界面开始与 DeepSeek 对话啦!

17+使用平替:
- 硅基流动:https://cloud.siliconflow.cn/i/snHnLED8
- 国家超算中心 https://chat.scnet.cn/#/home
- 百度云千帆:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
- 英伟达NIM:https://build.nvidia.com/deepseek-ai/deepseek-r1
- Groq:https://groq.com/
- Fireworks:https://fireworks.ai/models/fireworks/deepseek-r1
- Chutes:https://chutes.ai/app/chute/
- Github:https://github.com/marketplace/models/azureml-deepseek/DeepSeek-R1/playground 🚫
- POE:https://poe.com/DeepSeek-R1 🚫
- Cursor:https://cursor.sh/ 🚫
- MonicaAI:https://monica.im/invitation?c=ACZ7WJJ9 🚫
- Lambda:https://lambdalabs.com/ 🚫
- Cerebras:https://cerebras.ai 🚫
- Perplexity:https://www.perplexity.ai 🚫
- 阿里云百炼:https://api.together.ai/playground/chat/deepseek-ai/DeepSeek-R1
- Windsurf:https://codeium.com/windsurf
- DeepSeek伴侣:https://ds.huasheng.ai/
🚫 为需要魔法
本地部署DeepSeek
什么是本地部署?
简单说就是把在线的大语言模型,安装在你家的电脑上使用,拔掉网线也能继续使用,这样做有以下几个好处。
本地部署的好处
- 更稳定更快:离线使用,无需联网,减少网络依赖和延迟
- 模型可控性:根据自身对模型进行定制和优化
- 数据安全:避免了将敏感信息上传至云端,降低了数据泄露风险
- 成本控制:无限免费使用,无需支付订阅费用
不建议部署R1
这部分本来想写【部署方式】,网上也有很多教程,但想来想去,写出来反而是浪费大家时间,其实对于咱们普通用户,根本没必要,原因有二:
- 满血版 DeepSeek 硬件配置需求极高,价格需要200万以上
- 如果不部署满血版,蒸馏版的7B模型使用体验很差,不如不部署
索性咱也别浪费时间鼓捣了,如果你实在想要部署,直接看这几个教程:
方法①:使用 ollama+PageAssist 插件部署
方法②:使用 LM Studio 部署
视频教程:DeepSeek R1 推理模型完全本地部署保姆级教程
附件:网上别人传的本地部署「Deepseek 大礼包」
- DeepSeek R1 7b 模型整合包,开箱即用。
- 2025 年 DeepSeek 桌面版:一键安装,轻松体验桌面版强大功能。
- 破除限制文件补丁:解锁 DeepSeek 全部潜能,突破使用限制。
本地部署其他大模型
DeepSeek基础技巧
0. R1 推理模型与基础模型使用差异

1. 深度思考和联网搜索
- 深度思考:激活R1推理模型,适用于理解和解决复杂逻辑问题
- 联网搜索:结合网络最新信息,提供更准确、实时的回答
这两个功能都必须手动打开,才能使用,不选择【深度思考】默认的模型是V3,擅长基于知识库快速回答,没有高级推理的思考过程。
三种模式对比测试
我们的测试问题基于最近大火的《哪吒2》:
2025年春节档电影《哪吒2》目前票房已达多少亿?请结合其3D动画制作成本、观众口碑评分与同期竞争对手《流浪地球3》的排片率,预测该片能否打破中国影史票房纪录,并分析其对国产动画产业链的长期影响。
这里有几个坑:
-《哪吒2》的实时票房需要联网检索
-《流量地球3》2025春节并未上映,是虚假信息
- 预测是否能打破中国影史票房记录,其实已经打破
我们看对比结果:
同时开启深度思考+联网搜索
读取了47个网页,思考了48秒,完美避开了所有坑,并且指出了虚假信息,得出正确结论。

开启深度思考,无联网
回答截图太长,这里不放了,尽管有推理,但无法验证“信息真实性”,只能依靠时效性较差的知识库回答,所以无法获得真正的实时票房,无法识别虚假信息和做出最终正确判断。
开启联网,无深度思考
虽然读取了50多个网页,但是由于取法推理思考,这种复杂问题很容易产生AI幻觉,回答错误,也就是虽然有网络,但是脑子不够聪明,转不过来。
2. 提示词3个心法
相比于传统模型,我们需要事无巨细地提供思路、信息、方案,才能获得较好效果,R1模型需要的提示变得更简单,它会发挥主观能动性,深刻、准确理解用户意图,自己寻找解题思路。
之前的通用模型是指令型,像是需要你事无巨细指导的实习生;R1是推理大模型,像是猎头刚刚挖来的职业经理人,告诉TA你的目标,他会自己思考如何实现。
但这并不是说,你可以“省略必要信息”,该给还是得给,我把提示思路简化为了三个技巧:具体、详细、说人话。
具体
- 不具体:“写段春节祝福”
- 具体:“我是28岁设计公司打工人,写一段蛇年初一给直属领导王总的拜年祝福词,对方在意的是公司做大做强,可提及今年公司初创一起奋斗的经历,不超过150字。”
详细
如果你不知道怎么具体,那么只需要告诉AI四个核心信息:谁+做什么+补充细节+结果描述(包括格式、字数、输出要求等)。
比如:“我是机械专业本科生,需要优化文献综述部分,重点突出近 3 年柔性机器人传感器的突破,请用学术语言重写并标注参考文献 DOI。”
说人话
确保自己“说人话”,所说即所想,不用担心过于接地气它不懂或误解,然后可以暂时忘掉所有技巧,大道至简,会问就行,然后根据答案给出你的反馈,循环往复,像苏格拉底一样追问。
3. 四要素模板
如果上方的不好记,你也可以用网上大家总结的四要素模板:
[角色] 作为专家
[任务] 需要完成
[要求] 输出格式为,包含要素
[补充] 相关背景:,限制条件:
示例:
作为营养学顾问,需要为糖尿病患者设计一周食谱。
要求输出表格格式,包含早/中/晚餐的热量值。
相关背景:患者年龄65岁
限制条件:每日总热量<1800大卡
4. 万能提示词积木
有些提示词适用于任何场景,可以用简单几个词让AI理解你的意图,我称为【万能提示词】,这里有一份万能提示积木清单:点击查看
如果AI回复太晦涩,你可以:
- 说人话
- 请用通俗易懂的语言讲解
- 我是一个小学生,请用我能理解的语言回答
- 避免使用任何术语
类似的万能积木还有:
- 提供一个真实世界的案例
- 用类比和比较来解释
- 提供多个答案
- 如果你在回答前有任何问题,请向我提问
- 减少无关信息,只关注xxxxx
- 提供一步一步的指导(step-by-step)
- 是否还有其他的视角
- 请深入探讨xxxxx
- 输出为xxxxx格式
5. 指定输出格式
如果对框架感兴趣可以看这篇:万能提示词框架ABC
虽然说提示词不用特别复杂,但亲测输入格式的限定还是必要的,不然同一个简单的问题,比如“翻译”,它输出的结果会五花八门,就像这篇讲过的翻译结果混乱的问题。
想要提前规避,最好的方法就是指定输出格式。
你可以让输出格式结构化,比如输出为
- 表格
- Markdown/代码
- 列表
- 步骤
- 图表
- ……
如果输出结构复杂,你也可以直接提供示例,如:
- 以xxx开始;
- 以xxx结束;
- 以如下格式“可能原因+结果+解决方案”
- 翻译结果以纯英文输出,不带双引号,不做任何解释
常用格式控制语法:
- 强制结构:使用“`包裹格式要求
- 占位符标记:用{{}}标注需填充内容
- 优先级符号:> 表示关键要求,! 表示禁止项
6. 限定文风转换
DeepSeek擅长模仿作家风格,但本质是基于文本模式的概率生成,并非真正"理解"风格,因此自然是哪位作家的作品多、网络信息丰富,就更擅长模仿谁。
🔍 我整理了几个最佳模仿对象:
- 王家卫:精确到分钟的时间戳/无意义但具象的物品计数/错位情感投射
- 例:"0.01公分/ 57小时后,这罐凤梨罐头会过期"
- 鲁迅:文言白话杂糅/递进式讽刺
- 例:"翻开报表一查,这报表没有年代,歪歪斜斜每页都写着’降本增效’"
- 张爱玲:通感比喻/华丽苍凉对照
- 例:"他的承诺像玻璃柜里的马卡龙,隔着霓虹灯看是粉色的,咬下去才发现芯子早已潮了"
- 金庸:四字短句/天地意象
- 例:"只见他双掌翻飞,竟将十六核CPU的热浪化作太极气劲,散热器隐隐发出龙吟之声"
- 莎士比亚:ABAB押韵/命运诘问
- 例:"这电量啊电量,你为何像朱丽叶的容颜般易逝?"
- 海明威:动作串联/隐藏情绪
- 例:"他打开冰箱。取出啤酒。看了看生产日期。把易拉罐捏扁。窗外在下雨。"
操作方法
作家风格移植:
"请以[作家]的风格,创作/改写关于[主题]的内容"
"请用[作家A]的XX风格结合[作家B]的XX手法,描述[日常事物/科技现象/社会热点]"
还延展出另一种文体杂交等不同方式,例如:
"将产品说明书改写成《史记》列传格式
混合风格案例
-
王家卫×程序员周报
「2023年Q4第三周,星期三下午3点42分,IDE显示我修改了768行代码。他们说这叫敏捷开发,可阿May走后,再没人懂我为什么要给变量起名叫happy_ending。合并请求通过那天,我吃了整整三十粒章鱼小丸子——原来需求文档和爱情一样,改着改着就面目全非。」 -
鲁迅×星座运势
「大抵是水逆到了极致。狮子座的骄傲,在这几日竟显出些阿Q精神来。投资理财栏分明写着’不宜’,偏要买那虚拟币,仿佛这样便战胜了星盘。殊不知运势就像未庄的月亮,照赵家的便圆,照你的总是缺着。」 -
金庸×智能家居说明
「此扫地机器人曾于华山之巅修炼九年,自创’凌波微步清洁大法’。遇宠物毛团则使出乾坤大挪移,电量不足时更有梯云纵绝技直返基站。注:若见它深夜自行启动,莫慌,此乃闭关突破AI心法第三重境。」 -
莎士比亚×奶茶测评
「珍珠!你这来自东方的诱惑精灵!
是让罗密欧忘却朱丽叶的甜蜜毒药,
当黑糖裹挟茶汤穿越唇齿的瞬间,
人类啊,终于懂得特洛伊为何沦陷!」
DeepSeek进阶技巧
这部分未完成,还在继续补充……
1. 领域穿透
领域穿透技术通俗来说,就是用其他领域的知识或方法,解决本领域看似不相关的问题。就像武侠小说里的“隔山打牛”,用物理学原理分析奶茶店排队,或用艺术思维设计科技产品,这是AI很擅长的一种玩法。
行业黑话破解 → "解释Web3领域的’胖协议瘦应用’理论"
知识边界测试 → "用相对论原理分析奶茶店排队现象"
思维破壁指令 → "如果达芬奇穿越到现代设计智能家居,会提出什么方案"
领域穿透技术的核心是打破思维壁垒,可以有不同形式,比如:
- 技术穿透:如NAT穿透让内外网互通
- 学科穿透:用物理原理解释社会现象
- 时空穿透:让历史天才解决现代问题
下次遇到难题或很难理解的学科时,试试“不按套路出牌”,用完全不相干的领域知识降维打击!
场景化实战策略
商业决策支持
"假设我们要在曼谷开重庆火锅店:
列出当地餐饮法规的三个关键注意点
对比三个竞争对手的优劣势
用SWOT分析给出选址建议
要求:数据截止2023年Q2,考虑雨季影响"
创意内容生成
"创作科幻微小说:
核心冲突:AI获得诺贝尔文学奖引发的社会争议
关键道具:能修改现实的量子钢笔
风格要求:模仿刘慈欣的宏观叙事+东野圭吾的反转设计
限制:在1500字内完成三次剧情转折"
技术方案论证
"作为CTO评审区块链存证项目:
找出PoW机制在本场景中的三个不适用点
提出改进方案(需兼容现有智能合约)
用医院病历管理案例做推演验证
附加要求:绘制技术演进路线图(文 字描述版)"
DeepSeek介绍附录
DeepSeek(深度求索)是一家专注于人工智能基础技术研究的科技公司,致力于探索AGI(通用人工智能)的实现路径,公司背景:
- 成立时间:2023年
- 总部:中国杭州
- 定位:聚焦大模型研发与应用,提供高效、安全、可控的AI技术解决方案。
2025 年 2 月 2 日,据彭博社报道,由 DeepSeek 开发的人工智能助手在全球范围内掀起了一股热潮。这款推理型 AI 聊天机器人自 2025 年初发布以来,迅速攀升至 140 个国家的苹果 App Store 下载排行榜首位,并在美国的 Android Play Store 中同样占据榜首位置。
企业官网
官方地址:https://www.deepseek.com/
APP下载:https://download.deepseek.com/app/
官方频道
微信公众号:DeepSeek
小红书:@DeepSeek(deepseek_ai)
X (Twitter) : DeepSeek (@deepseek_ai)
创始人信息
- 背景:80后,浙江大学电子工程系人工智能方向毕业,本土背景。
- 特点:兼具强大的infra工程能力和模型研究能力,学习能力强,像极客而非老板。
- 理念:强调“是非观”置于“利害观”之前,倡导原创式创新。
- 教育背景:浙江大学
DeepSeek 创始人梁文锋,1985 年出生于广东省湛江市。梁文锋从小成绩优异,小学六年级时他就通过考试被吴川一中录用。一直是学校里的“尖子生”并在数学学科表现出极大天赋。
2002 年,梁文锋 17 岁,以吴川一中“高考状元”的成绩考上浙大本科电子信息工程专业,于 2007 年考上浙江大学信息与通信工程专业研究生。
2013 年,梁文锋与浙大同学徐进共同创立了杭州雅克比投资管理有限公司,两年后又成立了杭州幻方科技有限公司,致力于通过数学和人工智能进行量化投资。
2021 年,幻方的资产管理规模突破千亿大关,2023 年,他宣布将正式进军通用人工智能领域,并创办了深度求索 DeepSeek,专注于做真正人类级别的人工智能。
近日这名 85 后还现身《新闻联播》以 AI 初创公司深度求索(DeepSeek)创始人的身份参加了一场国家超高规格座谈会,并现场发言。
创始人履历

团队信息
从目前已有的媒体公开报道中可以看出,DeepSeek 团队最大的特点是名校、年轻,即使是团队 Leader 级别,年纪也多在 35 岁以下。不到 140 人的团队,工程师和研发人员几乎都来自清华大学、北京大学、中山大学、北京邮电大学等国内顶尖高校,工作时间都不长。
团队里程碑
| 时间 | 关键事件 | 突破性意义 |
|---|---|---|
| 2008 | 开启量化对冲研究 | 本土量化探索先驱 |
| 2015 | 创立幻方量化 | 打造千亿级量化私募 |
| 2016 | 上线首套AI投资策略 | 量化投资AI化革命 |
| 2019 | 自研“萤火一号”AI集群(1100 GPU) | 算力储备超前布局 |
| 2021 | “萤火二号”投入运营(10亿/1万A100) | 算力规模比肩科技巨头 |
| 2023.07 | 创立DeepSeek | AGI探索新起点 |
| 2024.05 | DeepSeek V2引发行业价格战 | 推理成本降至GPT-4 Turbo 1/70 |
| 2024.12 | DeepSeek V3 685B超越Llama3.2 405B | 训练成本仅为Meta的1/9 |
{kind=link}